R&D

Closing the sim-to-real gap requires an integrated approach that combines domain randomization to build feature invariance with domain adaptation to align synthetic and real data distributions. This guide details how leveraging engineered entropy and high-fidelity sensor modeling enables perception engineers to achieve production-ready reliability in high-stakes autonomous systems.
How do you bridge the sim-to-real gap in computer vision? Closing the reality gap requires an integrated strategy that combines Domain Randomization (DR) to force feature invariance and Domain Adaptation (DA) to align synthetic and real data distributions. By engineering entropy in simulated environments and utilizing adversarial feature learning, developers can deploy robust perception models that generalize to chaotic, real-world conditions without exhaustive manual annotation.
What is the Sim-to-Real Gap?
The simulation-to-reality, or "sim-to-real," gap is the performance degradation observed when a model trained in a virtual environment is deployed on physical hardware. This discrepancy is categorized into three primary dimensions:
The Appearance Gap: Pixel-level differences caused by simplified rendering, lighting inaccuracies, and the absence of authentic sensor noise.
The Content Gap: Disparities in scene composition, such as the diversity of objects, presence of distractors, and environmental complexity.
The Dynamics Gap: Inconsistencies between simulated physics (friction, mass, contact forces) and the stochastic nature of real-world mechanics.
For industrial applications, such as defect detection, this gap is exacerbated by extreme data imbalance. A model may need to identify a single hairline crack in 200,000 perfect components, making synthetic data generation essential for coverage of rare edge cases.
How Does Domain Randomization (DR) Build Model Robustness?
Domain randomization operates on the principle that if a model is exposed to a sufficiently high range of variations in simulation, the real world will appear as just another variation. This forces the neural network to ignore superficial visual cues and focus on essential structural features.
Core Principles of Tobin et al. (2017)
The seminal research by Tobin and colleagues demonstrated that an object detector accurate to 1.5 cm could be trained using only non-photorealistic synthetic data. The methodology involves randomizing:
Textures: Assigning non-realistic, algorithmically generated patterns to all surfaces; performance degrades if fewer than 1,000 unique textures are used.
Lighting: Randomizing the number, intensity, and color temperature of point lights.
Camera Perturbations: Randomizing the position, orientation, and field of view to avoid dependency on a fixed viewpoint.
Distractors: Including random "flying objects" and clutter to ensure the system differentiates target objects from irrelevant background noise.
Automatic Domain Randomization (ADR)
OpenAI expanded this concept with Automatic Domain Randomization (ADR) to solve high-complexity manipulation tasks, such as a robotic hand solving a Rubik’s cube. ADR creates a curriculum where the difficulty of the randomization (e.g., mass, friction, surface materials) increases as the model reaches specific performance thresholds. This induces "emergent meta-learning," allowing the model to adapt to changing system parameters at deployment time.
Aligning Distributions with Domain Adaptation (DA)
While DR broadens the training distribution, Domain Adaptation focuses on aligning the features of the source (simulated) and target (real) domains.
Domain-Adversarial Neural Networks (DANN)
One of the most effective frameworks for unsupervised adaptation is the Domain-Adversarial Neural Network (DANN). DANN uses an adversarial process to learn features that are discriminative for the main task but indiscriminate regarding the domain. A Gradient Reversal Layer (GRL) is placed between the feature extractor and a domain classifier. The objective function can be described as:
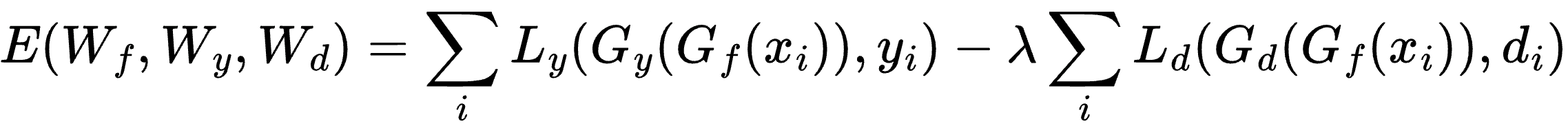
This forces the model to learn domain-invariant features, effectively "fooling" the classifier into being unable to distinguish between synthetic and real data origins.
Style Transfer and CycleGAN
Image-to-image translation via CycleGAN bridges the appearance gap by translating synthetic images into a "real" visual style without requiring paired datasets. This allows practitioners to "realify" synthetic data, adding textures and shadows from the target environment while preserving the ground-truth labels generated by the simulator.
Closing the Gap with Photorealistic Rendering and Physics
While randomization is powerful, high-precision tasks—such as sub-millimeter part inspection—benefit from narrowing the gap at the source through high-fidelity rendering.
Methodology | Philosophical Goal | Primary Strength |
Photorealistic Rendering | Close the gap by making simulation equal to reality. | Precision; essential for fine-grained segmentation. |
Domain Randomization | Bridge the gap by making models invariant to simulation differences. | Robustness; effective for navigation in unpredictable environments. |
Platforms like Repli5 facilitate this through CAD-to-Dataset workflows, which procedurally generate physically accurate datasets with depth and semantic labels directly from 3D files. These are then enhanced via generative augmentation to simulate lighting and weather variations while maintaining perfect annotation density.
The Critical Role of Sensor Noise Modeling
A frequently underestimated factor in the appearance gap is sensor noise. Real-world cameras introduce photon shot noise, readout noise, and quantization errors. Recent research favors non-parametric noise models that build probability mass functions (PMFs) from real-world captures. Calibrating axial and lateral noise for 3D cameras ensures that perception systems for tasks like robotic bin picking remain resilient to the specific noise profiles of deployment hardware.
Hybrid Training: The 1:1 Rule
The most robust sim-to-real performance is often achieved through hybrid training regimes. Recent NVIDIA research (2025) suggests that a 1:1 mixture of real and synthetic images can yield higher accuracy than models trained exclusively on real data, as synthetic samples provide critical coverage of rare viewpoints and adverse conditions.
By using techniques like Unbalanced Optimal Transport (UOT), engineers can align learned feature spaces even when simulation data is abundant and real-world data is scarce.
Future Outlook: Neural Rendering and Gaussian Splatting
The field is shifting toward real-to-sim-to-real pipelines using technologies like 3D Gaussian Splatting (GSWorld). These systems reconstruct real-world environments with photorealistic fidelity and integrate them with physics engines. This allows for zero-shot transfer because the control and observation spaces in simulation match the robot's native hardware APIs exactly.
Conclusion for Perception Engineers
Bridging the reality gap is no longer a matter of volume-based data collection, but rather strategic entropy engineering. By utilizing platforms like Repli5 to automate domain randomization and integrate high-fidelity sensor modeling, teams can move beyond 80% accuracy toward production-ready reliability in high-stakes autonomous systems.
Frequently Asked Questions (FAQ)
Does synthetic data need to look realistic? Not necessarily. Research like Tobin et al. (2017) shows that "intentionally non-realistic" textures are highly effective for object localization, provided the randomization is diverse enough to force the model to learn invariant geometric features.
What is the most effective way to combine real and synthetic data? Hybrid training with a balanced mixture (e.g., 1:1) is often the state-of-the-art approach. This allows the model to leverage the scale and ground-truth precision of synthetic data while anchoring to the visual nuances of the real domain.
How do you model camera noise for simulation? The most accurate method is to use physics-based statistical models or non-parametric PMFs derived from real sensors at various ISO levels, rather than simple Gaussian noise, to capture the heteroscedastic nature of digital sensor interference.

